
there are 62 posts from December 2009
not enough.
John Maeda’s Life Countdown: “How many more springs might I see?”
more on metadata and digital publishing
Edward Vielmetti has an interesting take on Ben Hammersley’s post from yesterday re. metadata and publishing…
Metadata only works when you un-meta it and deal with it again as data. The list of metadata elements that I care enough to keep updating is not just meta; it’s a first class real list, one that has to be treated as a first class citizen and not just some accidental system artifact.
Three points that have been rattling about in my head since reading Ben’s and now Ed’s post.
First, capturing and associating the metadata necessary for publishers needs to be as natural as possible. For a writer / journalist / blogger, or any type of content creator, that means that it not only needs to be part of the workflow, but it needs to actually add value to the piece they’re creating. Hyperlinks are a simple example of this; they can illustrate a point, add context for the reader, act as a punchline. And annotating content with hyperlinks has become an easy and natural part of the writing process.
Second, workflow should focus on the things where humans add value; hyperlinks are obviously one, and non-obvious contextual tagging. Let machines do the obvious stuff – scanning for proper nouns, place names, company names, addresses / locations, stock symbols, etc.
And third, as I’ve pointed out a few times here, I think the biggest challenge will be integrating the social and the real-time into the digital magazine experience. Clay Shirky made a great point at SxSW this year: that basically by definition content that’s more than about 500 words long is not about now. So, what’s the best way to connect content that was about then with a community experience that is about now? And how can all this (meta)data help?
i love chicago, really!
Sean Parnell: Chicago’s weather.
40 below (-40C)
Hollywood disintegrates.
Chicago’s Girl Scouts begin selling cookies door to door.
Via David Jacobs.
this is bloody messy
When the Facebook data team released a bunch of data about diversity on their network, my first thought was “Oh, man – can’t wait to read Danah Boyd’s blog on this…” Here she is, with a terrific understatement (“Of course, this is bloody messy.”) and a crucial point on the different levels of access to social media.
It’s not just a question of what you get to experience with your access, but what you get to experience with your friend group with access. In other words, if you’re friends with 24/7 always-on geeks, what you’re experiencing with social media is very different than if you’re experiencing social media in a community where your friends all spend 12+ hours a day doing a form of labor that doesn’t allow access to internet technologies.
Worth reading in full.
it's the metadata, stupid
Ben Hammersley comes through with part two of his three part series on what needs to happen to magazine publishing to take advantage of digital distribution. The key? Metadata.
The necessity above all else of keeping your metadata might seem like a geeky affectation – something that is really only of interest to librarians (itself not a bad reason) or trainspotterish data-completists – but it is in fact the simplest and cheapest route for a publisher to future-proof their business.
And…
So why do everything you can to keep metadata intact? Because it’s from this information that new products can be automatically created, at a scale and rapidity that would be impossible otherwise. With every piece of metadata that you don’t throw away, you gain a factor more potential ways of slicing through your content and delivering it as a separate product, simply as a result of a database lookup.
See also Fred Wilson’s post today, People First, Machines Second:
But 8tracks can now take the human intellligence that is contained in all of those playlists and do something interesting. They can have their machines go through all of them and create a ‘best of best of’ playlist. It could be just the most popular tracks across all of the best of 2009 playlists or it could be weighted by the times each playlist was played or it could be some other algorithm. My point is simple, if humans are doing the curation upfront, then you can turn the machines loose and get some interesting results.
if you don't have anything nice to say...
Just getting around to NY Mag’s piece on The Warm-Fuzzy Web:
In this new world of nice netiquette, technology is designed to make it easier for everyone to love one another. After all, if you’re not your “real self” online, how will Leighton Meester know it’s you who loved her dress at the Teen Choice Awards?
Gold stars welcome on this post. After all, how else will I know that you love my oh-so-last-week link blogging?
from viral loops to game driven marketing
I’m only a casual gamer, but I always enjoy reading Dan Cook’s blog Lost Garden. Today he posted a few notes on where he sees the web-based Flash game market going in 2010; this item sticks out:
As developers figure out that the game lives in the cloud not on a portal, they’ll start treating social networks as one of many marketing channels and stop equating ‘social game’ with Facebook alone. Viral loops will evolve into game driven marketing, a set of highly scalable, automated, experimentally verified techniques that drive an exponential acquisition of players. You need a server, you need players, you need a method of communication and notification. You do not however need a social network per se. Expect modular marketing systems built into some high end games that target multiple social networks, consoles, email address books, flash portals and any other concentrated source of potential customers.
fred's top 10
One of my favorite music bloggers just also happens to be a well-known venture capitalist. Here’s Fred Wilson’s Top 10 Records of 2009.
jonathan rosenberg posted a 4,400 word rorschach test
Jonathan Rosenberg, Google:
There are two components to our definition of open: open technology and open information. Open technology includes open source, meaning we release and actively support code that helps grow the Internet, and open standards, meaning we adhere to accepted standards and, if none exist, work to create standards that improve the entire Internet (and not just benefit Google). Open information means that when we have information about users we use it to provide something that is valuable to them, we are transparent about what information we have about them, and we give them ultimate control over their information.
Google talks a lot about openness and their commitment to open source software. What they are really doing is practicing a classic business strategy known as “commoditizing the complement“. Google makes 99% of their revenue by selling text ads for things like plane tickets, dvd players and malpractice lawyers. Many of these ads are syndicated to non-Google properties. But the anchor that gives Google their best “inventory” is the main search engine at Google.com. And the secret sauce behind Google.com is the algorithm for ranking search results. If Google is really committed to openness, it is this algorithm that they need to open source.
When I say the Twitter API may be an open standard, I mean something different than when Jonathan Rosenberg says Google likes open standards. I mean it’s open in that anyone can implement it now. A smart developer can implement the Twitter API in a matter of weeks. Rosenberg means that the process of defining the standard is open. He would start a process to define a standard that in two or three years a team of 20 programmers could implement in another two or three years. Those are the kind of results that his version of “open” delivers.
It all sounds great and Google certainly is a champion of open systems with Android and Chrome and countless other projects. Google is making a very public effort to claim the mantle of openness. But the battle for this mantle has been going on for a long time. Two years ago, I wrote a post titled “Who Is The Opennest Of Them All?”. What I noted then bears repeating. (…)
Open intent is great. No person or business should need to or advertise being open. But if you are as big as Tiger Woods, Google, or Goldman Sachs you are best to just leave the subject alone and just be great at what you do. Or buy your damn stock back, and talk about how closed you can be. That would be cool too.
UPDATE: And John Gruber:
It’s the biggest pile of horseshit I’ve ever seen from Google.
that's not art
Your new favorite blog for the next seven minutes: That’s Not Art, from Garrett Murray.
People post ridiculous “art” to Tumblr. These pieces frequently make it into Popular. I reblog them here and call them out for being stupid.
More like this, please.
where finished = done
Anil has two really great and non-obvious points for developers in his post The Twitter API is Finished. First, support RSD (yes!). Second, overload the source element.
The source element of status updates in the Twitter API is very interestingly open-ended, and supports use of URLs. Instead of merely advertising your client app, smart use of rel attributes and URLs here could help bootstrap some very interesting new potential.
transitioning to all knowing digital
Ben Hammersley, who knows a thing or two about online and magazines, shifts the perspective a bit on the design challenge for e-books. Yes, it’s about the form factor of the device…but it’s also about the editorial and production workflow.
So a real design challenge for e-books isn’t to design the user experience (which is dependent at the end of the day on the device capabilities anyway, which are pretty much unknown) but rather on designing a system that would allow existing publishers to transition their operations from ramshackle print to All Knowing Digital. We already know much of this: you can take the lessons from blogging CMSs, add in photography handling from places like Photoshelter, combine metadata collection from sources like Google Maps and OpenCalais, and version control from Git, and you’re halfway there. Combine it with process changes, where you require writers to file direct to a system that forces them to add in metadata for example, and you’re closer still. Of course, in two sentences I’ve described a process that really encompasses the whole old-media crisis, but I do think it’s a challenge that can be met.
This post is part one of three; looking forward to the sequels.
bonnier + berg's magazine tablet concept
There’s a ton to dive in to here, but the core difference I’ll point out between this concept and the Sports Illustrated one is Bonnier & BERG chose to focus on the user instead of the content. This wasn’t about the exclusive photos and real-time sports scores…this was about how a tablet could deliver a great experience for the user.
As for the social pieces: even though this demo was similarly light on demonstrating what the opportunities are for a rich, connected reader like this, I’d trust that this user-centered approach would lead to the right mix of ingredients.
very, very active.
Katie Spotz, who is planning to row across the Atlantic Ocean: “I see this as a form of active meditation.” Amazing.
the secret of the book
David Jacobs has been telling me that I absolutely have to read Bill Simmons’ The Book of Basketball; it’s 700 pages long and Simmons post on ESPN.com about the bits that didn’t make it into the book are what’s convincing me.
That, and grafs like this:
A big theme of my book is The Secret of winning basketball, something Isiah Thomas explains to me at a topless pool in Las Vegas. (The Secret, in a nutshell: Teams only win titles when their best players forget about statistics, sublimate their own games for the greater good and put their egos on hold.)
I like this Secret, and who wouldn’t want to hear stories about Isiah Thomas in Vegas? There goes my holiday break…
no such thing as a free pass
Marco Arment on the Vimeo thing: “YouTube was forced to comply with the legality of musical usage. Vimeo can’t expect a free pass simply because its founders are creative.”
spot instances
Amazon’s doing some interesting pricing innovation with EC2. The latest – spot instances. More info from Werner Vogels’ blog:
The central concept in this new option is that of the Spot Price, which we determine based on current supply and demand and will fluctuate periodically. If the maximum price a customer has bid exceeds the current Spot Price then their instances will be run, priced at the current Spot Price. If the Spot Price rises above the customer’s bid, their instances will be terminated and restarted (if the customer wants it restarted at all) when the Spot Price falls below the customer’s bid.
Clever, and plays to the strength of the Amazon cloud, which is its elasticity. As Vogels points out, spot instances are perfect for tasks that don’t need to be started / stopped at a particular time.
on the other hand, the trophy polish causes brain damage
The Man with the Yellow Hat: “Trophies make it hard to forget things you’ve done. Because you have to keep cleaning them.”
Via Merlin, who I fear is becoming obsessed with children’s lit and television. I’d stage an intervention, but it makes for a good blog read, so I’ll just sit back and enjoy the madness.
ideal syllabi
In the spirit of Jerry Saltz, Tyler Green asks his artists to pick their favorite / most-valued; first in the series is one of my favorite painters, Anne Appleby. She picks books by W.S. Merwin, Jim Harrison, Louise Erdrich, John O’Donohue and Susan Sontag. Look forward to the rest of the artists in Green’s series…
hidden nuggets
I love how folks are using foursquare tips to place little nuggets of content like this around the world; they’re mini blog posts for your friends, delivered to you based on where rather than when.
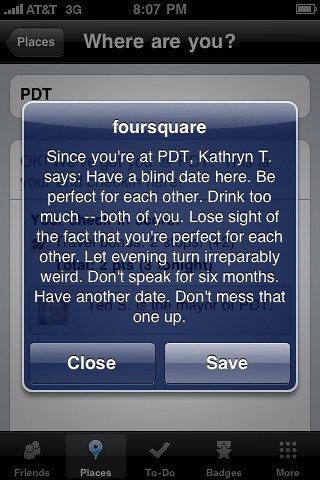
Found best @foursquare tip of all time tonight posted by Lock at Flickr
why what matters now just won't
I love Seth Godin as much as the next guy, but I’ll just come out and say it – there’s a 99% chance that I won’t read What Matters Now. It has nothing to do with the content – there are people in there that I enjoy and respect. Instead, it has everything to do with the form.
What Matters Now is distributed as an “ebook,” which is a fancy way of saying “a PDF.” This particular PDF is 82 pages long (one page per contributor), where some pages are designed as slides with illustrations, and some pages contain a micro-essay laid out in a two-column format. The only convenient PDF reading device happens to be a PC, and the likelihood of me shutting out the world and spending a couple of sessions with my laptop to read this ebook are slim to none (especially when there’s so much compelling YouTube content out there). And offline consumption isn’t really an option: I’m not really sure I want to chew up 82 pages worth of paper and printer ink on it, and I’ve learned that Amazon’s PDF conversion service for the Kindle will puke all over the two-column layout.
This should have been a website. Each essay with its own permalink. With interlinking between pieces. With hyperlinking out to the rest of the web. With search. And a table of contents. And commenting, favoriting and simple social sharing tools. And it could have been a beautiful thing to experience – on the web. Instead, it’s a file that I won’t experience, sitting in my Downloads folder.
how 'bout them apples
I’m obsessed with how nearly every single piece of media produced lately is simultaneously shipped with “behind the scenes” / “making of” footage and background info. Tonight’s example, this really clever spot from Draftfcb for City Harvest Food Rescue Organization.
Now go watch how it was made.
facebook product tagging
Contagious Magazine profiles a campaign from Forsman & Bodenfors for new Ikea store in Malmö, Sweden that used Facebook photo tagging in a very clever way: tag an item in a showroom photo with your name, win that item. (Via Ben Hammersley.)
the tail-eating snake of the web
There’s been a metric ton of bits spilled on content farms lately; Paul Kedrosky blogs about the “drive-by damage” this type of content has done as he tries to research a new washing machine.
Google has become a snake that too readily consumes its own keyword tail. Identify some words that show up in profitable searches – from appliances, to mesothelioma suits, to kayak lessons – churn out content cheaply and regularly, and you’re done. On the web, no-one knows you’re a content-grinder.
The result, however, is awful. Pages and pages of Google results that are just, for practical purposes, advertisements in the loose guise of articles, original or re-purposed. It hearkens back to the dark days of 1999, before Google arrived, when search had become largely useless, with results completely overwhelmed by spam and info-clutter.
rhbaby on the clash of the titans trailer
I have no idea what Clash of the Titans is even about, but thanks to rhbaby’s description of the just-pulled but just-before-that-leaked second trailer for the movie, now I have to see it.
The trailer got pulled, so below is an artist representation. First Zeus was all “Mortals suck!” and he would have thrown down some of the lightning - WHOOSHCRASH! - except he didn’t. Then we saw a glimpse of Pegasus and that rocked, and there was some dude with a sword and he was all “Mortals don’t suck!” and he ran some places, jumped around and then was all “WTF!? GIANT GODDAMN FUCKING SCORPIONS!!1!”
I won’t ruin the artist representation; click through for yourself.
and now? not so much.
James Surowiecki on Tiger Woods: “His appeal seemed to transcend sports, in the sense that his success was presented in things like the Accenture ads as exemplary not just of athletic ability, but of an approach to the world that other high-powered professionals could apply to their own jobs.”
pvrblog for sale
Matt Haughey has put PVRblog.com up for sale on eBay: 1,500+ posts, 11,000+ comments, current pagerank 6/10. Current bid $1,025; this auction will be fun to watch. (Though don’t forget to take clusterflock’s advice on how to buy on eBay.)
fanfilm
How much do you think you’d need to raise on Kickstarter to fund production of a David Lynch-ian version of Return of the Jedi?
facebook following
Now that Facebook is pushing the defaults to public (here’s Mark Zuckerberg’s wall, for instance) how long until they adopt an asymmetric follow model for individual profiles?
(Today the asymmetric follow is why fan pages exist, but if they were to dramatically simplify their offering they’d (a) collapse fan pages and profiles, (b) adopt asymmetric following, (c) put controls in place that enabled you to share content (e.g. pics of the kids) with limited sets of identified users, and (d) upsell brands (celebs, companies) on additional tools for their profile.)
the preference of monsters
Jeremy Denk (pianist, blogger) on the use of Schubert in Twilight: New Moon.
This was one of these moments where Popular Culture decides for a capricious instant that Hundreds Of Years Of The Western Canon are temporarily useful for appropriation; it does classical music a huge favor by Noticing It. Lovers of classical music are supposed to beam and pant like a petted dog, grateful for any and all attention. Wag wag, woof woof, good boy, go play in your cute tuxedo now!
Go read the whole thing. Even if you hate Twilight and have no idea who Schubert is.
the list to end all lists
Edward Champion’s top ten years of the deacde.
on a wave of schadenfreude
Nielsen Business Media is shuttering Kirkus Reviews. I’m sure there’s more than one author who won’t miss them.
Title of this post to be sung to the tune of this song.

when harry met sally at the dentist
Is it that obvious that I have a crush on Filmosophy? (Or does two links-in-one-week say more about Meg Ryan than it does about Filmosophy?)
Anyway – as previously mentioned, all this week Filmosophy is reviewing Meg Ryan movies. Today they did When Harry Met Sally. And since sharing is caring, I’ll share my own story about that movie. You can thank me later.
First, something you must know: I hate the dentist. Hate thinking about the dentist, hate going to the dentist, hate being at the dentist. I even hate the feeling of really smooth teeth after being at the dentist, because…you guessed it…it reminds me that I was just at the dentist.
So I’m at the dentist. And I have to have some procedure done that involves cotton balls and mouth guards and needles and drills and other shiny metal tools. But! Because my dentist is a wonderful person (really, she is, highly recommend her – I don’t hate her, per se, just her profession) she recognizes how much I hate this platonic dentist ideal, and agrees to dose me with a horse’s quantity of nitrous oxide.
God bless her.
And after the mask’s been on for a few minutes, the nurse (dental assistant? Whatever, I’m high at this point) asks if I’d like to watch a movie while my mouth is being excavated. I try to make a joke about “If I had known there was a DVD player I would have brought my own” but the mask was on and I was slurring my words pretty heavily. The DVD case was slim, so When Harry Met Sally it was.
Fast forward about 15 minutes. The movie’s queued up, I’ve had more of the nitrous, my gums have been shot full of Novacaine and they’re sharpening the drill bit on my molar. Harry and Sally get into the car for their roadtrip and Billy Crystal proceeds to spit sunflower seeds all over the inside of the passenger window because he had forgotten to roll it down.*
And I laugh. Out loud. Through the cotton balls and the mouth guard and the Novacaine and the nitrous and the drilling. And my dentist, God bless her, pauses to pull the drill out of my mouth, looks at me and says “Yeah, you’re doing fine.”
And that’s my When Harry Met Sally story.
* I love that moment in the film. (Much more than the tedious “can men and women be friends without sex getting in the way” conversation that follows; duh, of course not.)
we've always been at war with verizon
So the head of AT&T’s wireless unit made news today for having the gall to admit that their networks in San Francisco and New York “are performing at levels below our standards.” (No, really?)
But T’s corp comm folks didn’t see that as the news angle. As posted in an update to the WSJ piece linked above, their spokesman said:
“Ralph de la Vega made significant news today in saying that, based on independent drive testing, we have 98.68 percent nationwide voice retainability, which means that the difference between AT&T and the industry leader is less than 2/10 of a percentage point on this important metric. That translates to a difference of less than 2 calls out of a thousand.”
Cue the map.
james franco, performance artist
Actor James Franco is treating his 23 episode stint on General Hospital as performance art, and he has a great piece about what he’s doing in the Wall Street Journal.
I have been obsessed with performance art for over a decade—ever since the Mexican performance artist Guillermo Gómez-Peña came to visit my class at Cal Arts summer school. I finally took the plunge and experimented with the form myself when I signed on to appear on 20 episodes of “General Hospital” as the bad-boy artist “Franco, just Franco.” I disrupted the audience’s suspension of disbelief, because no matter how far I got into the character, I was going to be perceived as something that doesn’t belong to the incredibly stylized world of soap operas. Everyone watching would see an actor they recognized, a real person in a made-up world. In performance art, the outcome is uncertain—and this was no exception. My hope was for people to ask themselves if soap operas are really that far from entertainment that is considered critically legitimate. Whether they did was out of my hands.
[this is good]
a frickin' miracle
Tim Goodman on Elvis Costello’s Sundance Channel music show:
There are a lot of elements that make “Spectacle” the best music show on television, but the most important litmus test is that you can tune in and either not know or not like the guest, only to find the hour flying by because Costello, like only a fellow musician could, manages to get stories out of them that others (think Jay Leno) could never do. He even got [Lou] Reed to laugh last season.
Emphasis mine.
why i love six apart
Reason #4789, our IT manager sends out fantastic holiday gift ideas.
To: Six Apart SF Office
Subject: Cruel Like Me
If you have a Mac lover in the family and a cruel streak, I have lots of spare Macbook Pro boxes you can take to pack your non-Macbook Pro gifts in. Stop by and grab one. My daughter is going to get one just FILLED with socks.
elegant thinking
Redub LLC, Don’t Make Me Scroll: “What the screen lacks in dots per inch it more than makes up for in dots per inch per second.” (via)
an EC2-based proxy for spotify?
A chat from this morning, prompted by the apple + lala post.
friend: Spotify just needs to launch in the US
me: or i need to move to the uk
friend: I can’t believe somebody hasn’t figured out an ec2/europe proxy thing for it yet
me: someone probably has. and they’re just keeping it to themselves and their friends.
friend: ask on twitter? :)
So, has anyone done this? An persistent EC2-based proxy that gets US users into Spotify? (If I were really motivated I guess I could use this post on how to create a personal proxy server on EC2 as a guide…)
apple + lala
I’m enjoying the competing stories on just how much Apple paid for Lala:
- AllThingsD: Lala’s Fire Sale That Wasn’t: What Apple Really Paid
- TechCrunch: Lala was Bought by Apple for $17 Million, Not $80 Million
If you’re Apple, you want to do as much as possible to signal a bargain-basement purchase price.
First, a high price would validate the online streaming / music locker in the cloud product category, which from a product strategy perspective is about as far away from the current iPod / iPhone / iTunes distribution model as you can get. If they paid a lot for Lala, it would be a strong signal that that model’s outdated, and that they needed to rush to market (buy v. build) a better model. Remember that Apple rarely admits product/technology mistakes; when they bring a key new capability to market they act like they were the first ones to think of it (see video iPods).
Next, if they’re planning additional acquisitions in the online music space, the last thing you want to do is telegraph a premium price on the first deal you do. It’s a lot easeir for their corp dev team to look the next startup in the eye and tell them “well, Lala had these assets (users, tech, data) and we bought them for $X, so you’re only worth $Y.”
Finally, keeping that category marginalized (“it’s just a technology purchase”) potentially gives them better bargaining power if/when they need to negotiate streaming licenses from labels. (Though I seriously doubt that Apple hasn’t already negotiated streaming licenses; the fact that Lala’s licenses aren’t transferable is a red herring.)
That’s not to say that AllThingsD is right and Techcrunch wrong, just that if you were Apple you’re not really motivated to brag about how much you spent on Lala.
Now Lalapple, bring on that iPhone app we’ve been hearing so much about.
yesss. very powerful words.
Filmosophy reviews You’ve Got Mail.
I have been at some point in my growing up, so in this movie, so in love with the whole thing of it, that I wanted to buy armfuls of white t-shirts and olive green cardigans from The Gap and be that skinny, be “a lone reed”, wear a strappy wristwatch and go to Starbucks and maybe aim for bigger breasts and low-rise Dockers instead of pleat-front, but still, to this day, imagine he is walking just behind me on city blocks unnoticed, ordering me bouquets of sharpened pencils for Fall and stealing my business out from under me and making plans to ruin my life. Or something. Because that is love, we have learned, are reminded: we earn it, through unrelenting patience and saintlike forgiveness and cute-meet, Hollywood coincidence and E-MAIL.
Via The Awl, who quoted the meta-enabling bit re. how we’ve all been so busy doing email that we haven’t had a chance to discuss the ramifications of it yet, plus listicles (whatever those are); meanwhile I just liked this perfect description of mid-to-late-nineties Meg Ryan-ness.
Also, Filmosophy is set in Rockwell, which makes it that much better.
faster faster faster
Lost’s Damon Lindelof in an interview at TVGuide.com: “In Season 1 it took them eight episodes to build a raft; in Season 5, they jump through time four times in a single episode.”
the song remains the same
Dean Allen shuts down Favrd, and kicks off a new version the same discussion we’ve been having for 10+ years now.
On the one hand, our linked-to blogger, Jeffrey Zeldman:
That a community may no longer please its creator is hardly relevant. Once community exists, it is not about the person who created the conditions for its existence; it’s about the people who inhabit the space. If you don’t believe that, you have no business creating anything.
On the other hand, everyone’s favorite cranky commenter, Joe Clark:
The creator always has the right to say enough is enough. If you’re the sole proprietor, I lean more toward the side that gives you life-or-death control over the “community.” I don’t have a socialist model of online community for those cases.
Me? I just don’t understand how Dean stuck with it for as long as he did.
Update: I like Mike Monteiro’s take: “Now, we can all bitch about it being gone or we can go build something good enough that people will cry when it’s gone too.”
chicago's holiday train
Claudine Ise has a great post up at Bad at Sports about happening upon the Chicago Transit Authority’s fabled Holiday Train.
Everyone is grinning, laughing, excited that they’ve found the CTA equivalent of the golden ticket. Me most of all. The interior of the train glows red and green–a bit sickly, but still nice. There are tinsel and red bows everywhere. Even the rail poles are wrapped in candy cane striping. I cannot stop beaming – I know I look like an idiot but I don’t care. It’s the holiday train!
The photos are fantastic.
what was missing from the sports illustrated tablet concept
So on a second watch of the Sports Illustrated tablet concept reel, I was struck by something fundamental: while the content looked great and a magazine interlaced with full-motion content is definitely fun to look at and page through, they completely missed on what could make a device like a tablet so great: a connection. Specifically, a connection to other sports fans.
To be fair, there were two small nods towards community: the ability to share stories you read with your Facebook friends (yawn), and the ability to guess what happens in a sporting event you’re watching on TV before it happens. But they struck out* on any real integration of social into what’s otherwise a compelling media experience.
- Look at all those photos and videos of last week’s sporting events. How about aggregating fan photos/videos from Flickr or YouTube or Vimeo alongide the professionally produced content?
- Look at those quickstats on players. How about pulling in a live stream of tweets about that player, and a buzz index of who is being talked about (a la TweetZone)?
- How about a presence indicator of who else is reading this article right now, with an opportunity to connect with / chat with / connect to those sports fans?
- Or, shoot, how about just some comments on the article pages?
I know it’s completely unfair to bash a promotional concept video for missing features. But as I watched this video the phrase that popped into my head was “multimedia CD-ROM,” because for the most part that’s what’s demo’d here – in a new format, with a new delivery mechanism.
The tablet form factor could be a revolutionary medium for delivering compelling media experiences. But if publishers like Sports Illustrated view this as just another channel for delivering one-way content, they’re going to get knocked out* by the folks who figure out how to combine the best of both worlds – high-quality editorial content and a compelling social experience.
* Obligatory sports metaphors.
updated scoreboard
Matt Jacobs has updated his Canabalt scoreboard; it now includes data summarized by day, and scores for individual users. Plus, check out the beautiful chart!
convenience as interface
Khoi Vinh on the tradeoff of convenience v. highdef / hires: “You could re-interpret the idea of convenience as a format’s interface — if it’s easy to use, if it provides affordances commensurate to the needs of real users in actual use cases, then it will win over higher resolution. Actually, it’s the content that really matters.”
blogs + pandora + lala = amazing
I know I’m late to this party, but I just have to say that as a music lover the combination of music blogs, Pandora and Lala is amazing. Project for 2010 that I’m starting one month early: monthly playlists in Lala that bookmark the songs I’ve been listening to / discovered via music blogs & Pandora, purchased at the end of the month.
Update: case in point, SFJ just posted his best of 2009 list.
which reminds me
At Today and Tomorrow, Unstilled Stills by Laura Brothers; animated GIF interpretations of Clyfford Still paintings. Amazing.
(Which reminds me of this San Francisco Art Institute MFA show that we saw once where one of the grad students’ work was clearly “inspired” by Still, and one of the visiting art lovers had written in the artist’s guest book something to the effect of “I represent Clyfford Still’s estate and I’ll see you in court.” These animated GIFs are nothing like those rip-off paintings.)
respect
The Sartorialist on Bill Cunningham: “Everytime I think I’ve accomplished a little something with this blog, I think of him and realize I have another 35 years before I can even start feeling that way.”
new york times editors slain by the googlebot
The New York Times doesn’t even try to hide their Googly jealousy anymore. On Monday it was David Carr comparing Google to Al Qaeda with his 9/11 metaphor, and today it’s TV critic David Genzlinger laying it on thick with his review of Maria Bartiromo’s CNBC program “Inside the Mind of Google.”
Here’s my favorite snippet:
Ms. Bartiromo begins with an exceedingly gushy tour of Google’s headquarters in Mountain View, Calif., sounding as if she’s on the payroll of the company’s public-relations department. Such amazing cafeterias! Such wonderful employee perks! Such incredibly smart people everywhere!
It’s the kind of mush that makes you go channel surfing, especially the endless prattle about how smart everyone at Google is. Lots of businesses are full of smart people. Some of them are laying those smart people off because their business models have been undercut by Google. Newspapers, for instance.
That second graf is just begging to be slashed by the red pen. Aren’t there any editors over there anymore? Or were they all slain by the business model-destroying googlebot?
i want one of those
Tired: vanity domains. Wired: vanity IP addresses.
differentiated dns
David Jacobs points to OpenDNS founder David Ulevitch’s post on Google DNS. (Thanks, David!) The graf that DJ pulled is interesting, but so is this one:
It means that Google is bringing awareness to a wide audience that there is a choice when it comes to DNS and that users don’t have to settle for what their ISP provides. And we believe that having choice is a good thing — just as Internet users have unbundled their email to services like Gmail, Yahoo! Mail and Hotmail people have been unbundling their DNS and switching to OpenDNS in huge numbers for the last 3+ years because we’re better.
This is absolutely the case. I’d never even considered switching my DNS service on my laptop or home machines until today. And now I’ll probably try Google and/or OpenDNS. But users abandoned their ISP-provided email to the webmail services because of a radically better user experience, and I’m not sure that a DNS service provides that much opportunity for differentiation to even the mildly sophisticated Internet user (i.e. “one that even knows what DNS is”).
way below the fold
From Google Quick Search Box, my new favorite preferences dialog.*
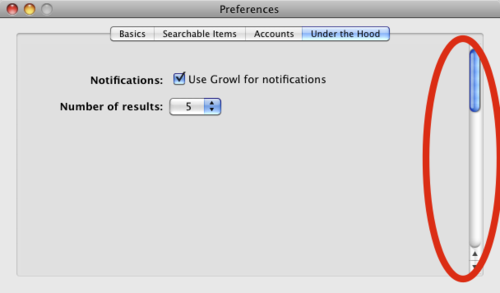
A new approach for “progressive disclosure,” hiding all the “way under the hood” stuff down below the fold where users won’t see it unless they scroll. (Then again, if you’ve installed QSB, you’re probably a user who’d scroll.)
* What, you don’t have one of those?
video killed the radio star
Sasha Frere-Jones unpacks Susan Boyle’s hit record, emphasis mine: “One reason that Boyle’s success might not have much to do with popular music is that, compared with television, popular music isn’t that popular.”
the startup visa
Great op-ed from Paul Kedrosky and Brad Feld in today’s WSJ proposing a startup visa. The challenge with getting something like this passed is having congresscritters understand this key point: “Would it work every time? Of course not. It would fail more often than not. Start-ups often fail.”
the six million dollar man
I’m sure this cost more than six million dollars, however: Experts: Man controlled robotic hand with thoughts.
After Petruzziello recovered from the microsurgery he underwent to implant the electrodes in his arm, it only took him a few days to master use of the robotic hand, Rossini said. By the time the experiment was over, the hand obeyed the commands it received from the man’s brain in 95 percent of cases.
In other news, who’s gonna go see Avatar with me?
something's wrong with the head
I love today’s installment of pictures for sad children.
[this is good]
Arianna Huffington: “Let’s be honest, while promiscuity is not good in relationships, it’s great for those looking for news and information.”
nice work, @joinred
I really like the execution of the @joinred campaign today on Twitter; good use of the product, one click simple install of the @joinred theme, and a subtle use of CSS styling to change the color of tweets coming from the @joinred account.
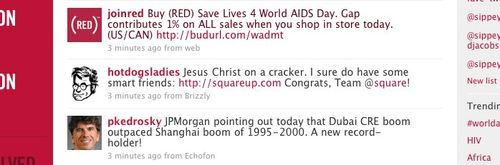
Well done.
left as rain
Your new favorite music blog for the next…let’s say…20 minutes.